上章我们还有个问题没有解决,就是我们读取的这个文本文件内容,打印出来是乱码的。
读取文本文件乱码有两个可能,我们前面研究过,第一个原因就是存乱了,很明显这是不太可能的。
因为这个文本文件我们是直接在pycharm里面创建写的,pycharm默认就会帮我们保存成UTH-8格式。

所以只能是第二个原因,就是取乱了。
当你用read()功能来读文件的时候,它会先向操作系统发请求,告诉操作系统:‘我要把这个文件的内容从硬盘读入到内存。’
而这个文件存的时候我们使用UTF-8存操硬盘的,我们这里指定的读取文件的模式又是t模式,t模式我们说了读写都是以str为单位的,而str我们又可以把它看成是Unicode。
所以read本质读取的是硬盘里的utf-8格式的二进制,但是由于t模式的存在,t模式会强制让read把读出来的utf-8格式的二进制转成Unicode。
t模式就会有这么一个解码的过程。
但是我们用open功能打开文件的时候,我们并没有指定utf-8编码方式来解码,我们没指定,那它一定会用一个它默认的编码来解。
由于open是对操作系统发请求的,这个文件也是由操作系统打开的,偶们对操作系统发请求的时候也没告诉操作系统用什么编码来打开文件,那操作系统就会用它默认的打开方式来打开。
在Linux和Mac上面默认的编码就是utf-8,而在Windows上面默认编码是GBK,所以你用的是Linux和Mac,你没指定编码方式的话就不会乱码,但是到了Windows平台上,就会出现乱码。
当然由于我们这个文件里的内容较少,这几个字所对应的编码数字刚好GBK里面也有,所以这里是乱码状态。
现在我多打几个字,这时候可能我信达的这些字uft-8编码对应的数字在GNK里面完全不存在吗,这时候乱码的机会都不会给我们。
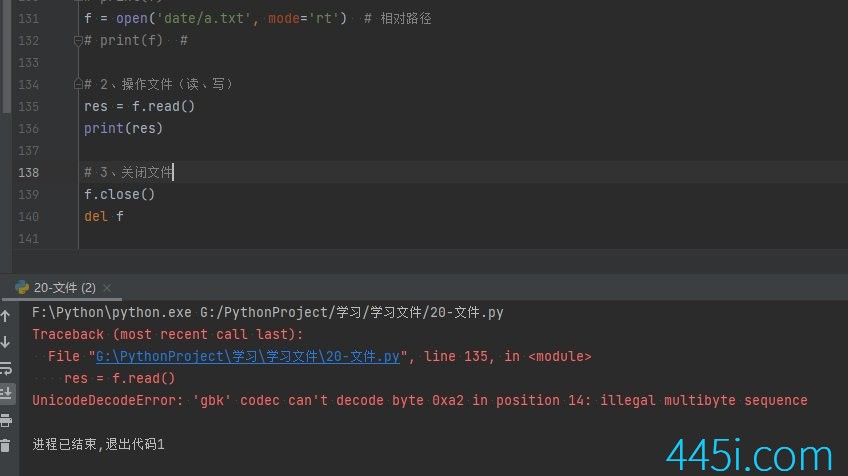
直接报错说Unicode解码错误。
针对这种不同平台的解码方式不同的情况,我们就应该给open功能指定一个encoding参数,让它等于utf-8。
f = open('date/a.txt', mode='rt', encoding='utf-8')这样解码的时候它就会告诉操作系统,你给我做好准备,我要按照utf-8的方式来打开这个文件,到了用read读的时候,它就会看你用的t模式那我应该把读出来的二进制数据转成Unicode。
然后看encoding参数,utf-8。那她就会按照utf-8来转Unicode。
这样读出来的数据就不会乱码了,

这是t模式下的读操作,如果是t模式下的写操作,也是一样的道理。
为了跨平台性,不管是什么操作系统,都应该指定encoding参数。
最重要的是只能是文本文件下才能这么操作。
未经允许不得转载:445IT之家 » Python 指定字符编码

