废了那么多的章节讲字符编码,最终只需要记住一个结论就行了,关于前两个阶段的乱码问题,我们只需要加上文件头就解决了。
这个文件头指定的编码方式,就指定成你保存文件时用的编码就可以了。
a = '人'这个变量值是直接存成了Unicode格式的对吧,前面我们提过,Unicode转成其他编码格式,这个过程我们叫编码,然后其他编码转成Unicode我们叫解码。
这个a下面有个方法叫encode。

这个方法叫编码,然后我传一个参数GBK给它。
a.encode('gbk')这就是把Unicode转成了GBK,然后用一个变量值来接收这个返回值,再打印一下这个res。
res = a.encode('gbk')
print(res, type(res)) 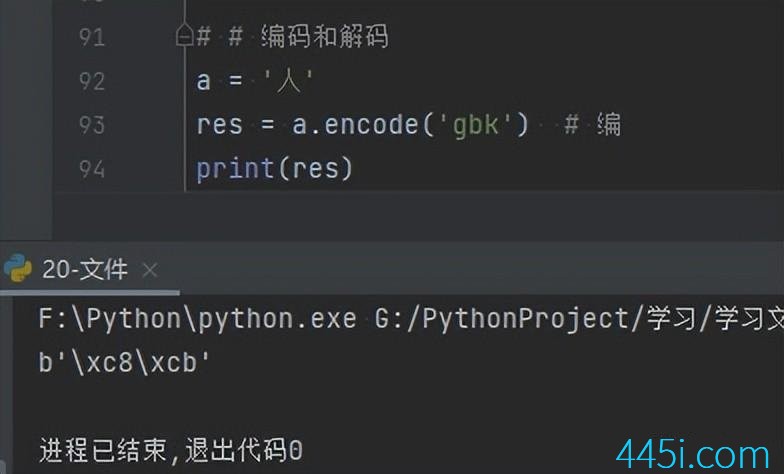
我们可以在网上找到,人这个字的Unicode编码转成GBK格式,Unicode是4EBA,转成GBK就是484B。
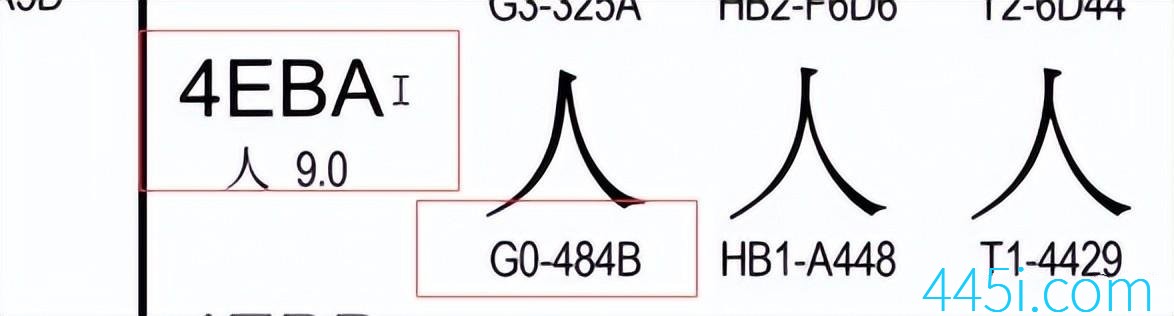
但是它真正存到硬盘里面,是需要加上标识头的,结果应该是C8CB,我们打印出来的是一样的。
前面还有个小写的b,我们再来打印下类型看。
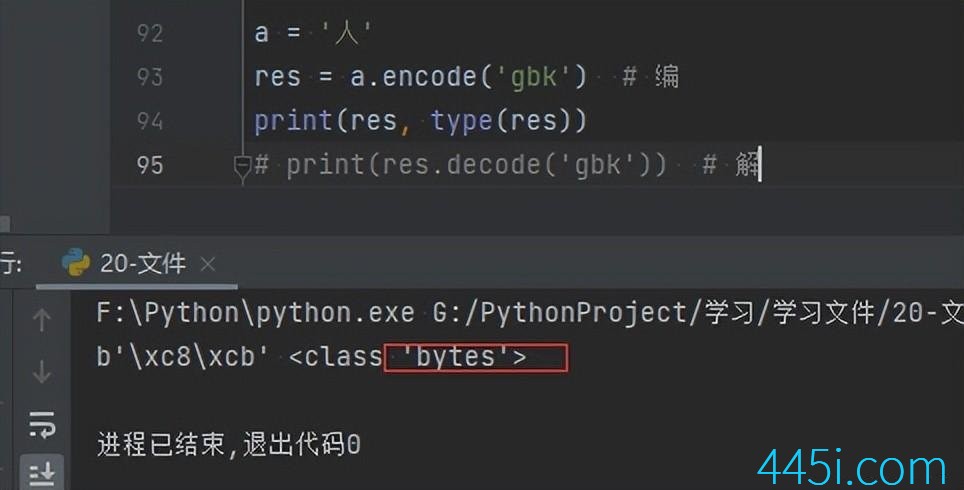
Unicode编码成其他格式,这个类型就叫bytes类型。
那Unicode转换成这种byets类型有什么用呢?说白了这个类型就是一串GBK格式的二进制嘛,只是我们打印出来看到的是16进制的,其实本质就是一串二进制数。
这串二进制数第一个用途就是可以写入到硬盘里去。
第二个用途就是可以研网络进行传输,比如你写的程序要和其他老的平台进行数据交互,老平台可能只识别GBK。
这时候我们python3的Unicode就不能直接传给对方了,要encode成GBK或者其他老平台支持的编码方式当然你也可以去尝试encode程UTF-8或者其他的都行。
好了,回归正题。
这个GBK我想转成Unicode就要对它进行解码了。
print(res.decode('gbk')) 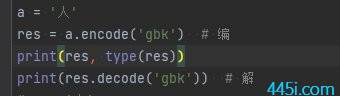
解码也是按GBK来解,再打印一下。
打印出来,又变成了人这个字符了。
关于字符编码的相关知识,到这里简单的就全部介绍完毕了,接下来要学习的就是怎么用python来操作文件。
未经允许不得转载:445IT之家 » Python 编码与解码


