字符编码的理论我们讲完了,现在我们实践验证一下,在python程序的运行过程中,怎么保证乱码问题。
我们运行python程序的过程中,不管是借助了python还是其他工具,本质就是在命令行里敲了python解释器,然后跟上Python文件的路径。
我们执行这个py文件之前,首先得写好这个python文件对吧!
我们写python程序就得用文本编辑工具,现在我们使用的pycharm就是一个文本编辑器。
现在我新建一个test.py文件,然后看屏幕的右下角。
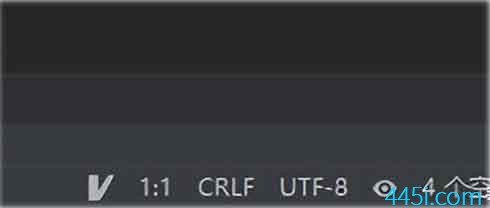
显示了一个UTF-8,然后我们点击它,就就可以选择GBK。
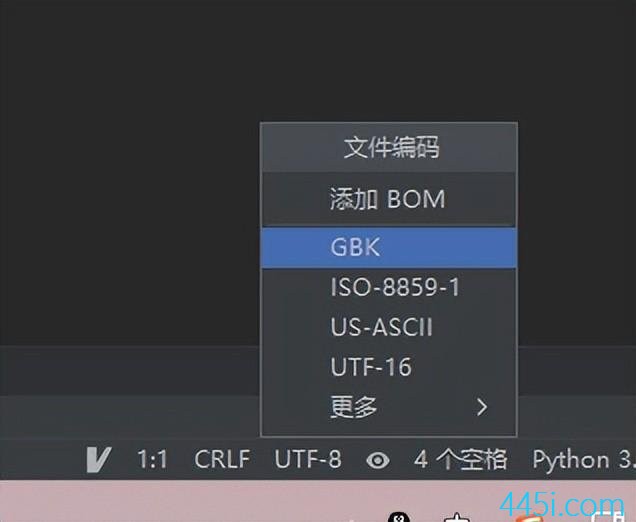
现在我们就把字符编码改掉了,这里要注意我们改的编码方式是改的存到硬盘的方式,而不是内存的。
然后我在这里先写一个注释。然后随便print一点东西。
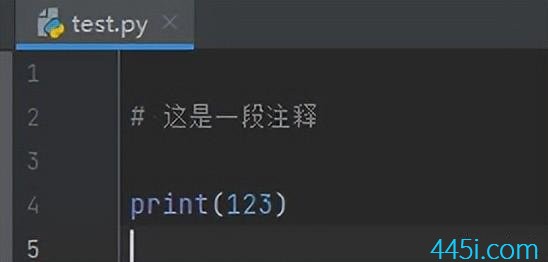
现在这段代码在内存里面是转成了Unicode格式的二进制了,接着保存。
保存的这个过程就是由内存了的Unicode编码,转成了我们指定的GBK编码,然后丢到硬盘里面去了。
现在在硬盘里存的是这段代码的GBK格式的二进制。
现在这个程序的开发我们已经做完了,然后我们现在试试把这个pycharm当做一个普通的文本编辑器,运行这个程序我们还是到命令行里面。
首先把这个文件的绝对路径复制一下。

然后放到cmd环境下运行。

前面我们说过,运行python程序有三个阶段,第一个阶段就是python解释器先启动,这时候就相当于启动了一个文本编辑器。
第二个阶段就是这个文本编辑器要把硬盘的这个文件内容,由硬盘读入到内存,注意内存的编码是Unicode编码的。所以这个文本编辑器会把这个文件内容转成Unicode。
第三个阶段其实按道理,当时按照什么编码方式存的这个文件,现在就应该按照什么编码方式来取。所以应该按照GBK编码来转成Unicode编码。
但是我们根本就不没告诉python解释器要用GBK来转,那么到底我们的python解释器会默认把这个文件按照什么编码方式来转成Unicode呢?
敲回车,我们发现报错了。
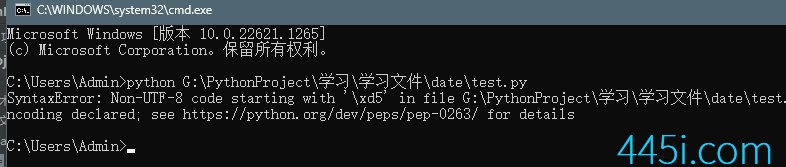
报错内容说语法错误,好像UTF-8出什么问题了。
现在我们猜也应该猜到了,我们现在用的这个python解释器默认读文件的编码就是UTF-8。
那么我们怎么来告诉python解释器不要用它默认的编码方式来读取文件,而是要用我告诉它的编码方式呢?
未经允许不得转载:445IT之家 » 零基础Python到全栈-py文件乱码问题


